Fine-Tuning or RAG - Why not Both?
Sep 28, 2023
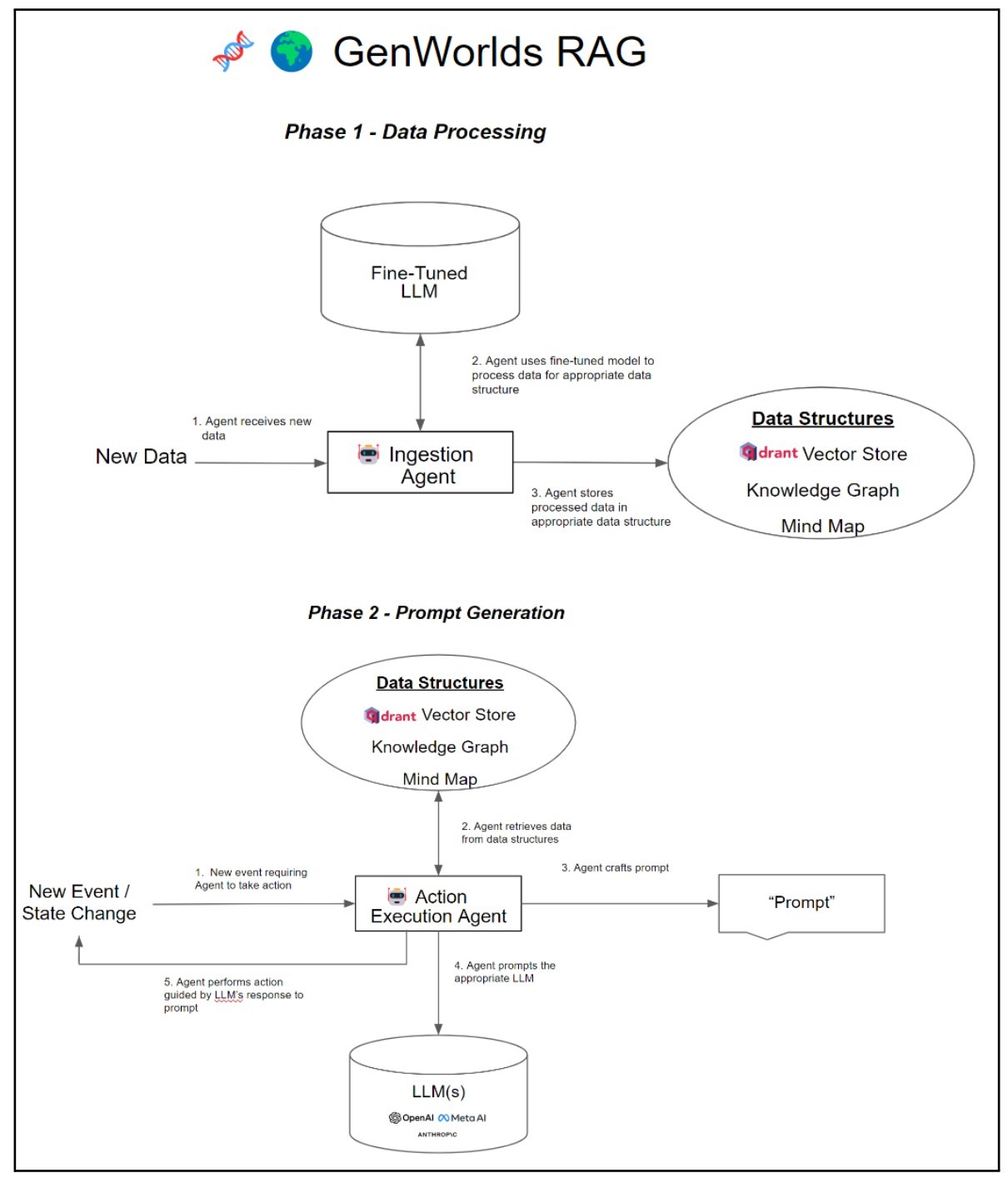
In many conversations with customers and investors, we are often asked if we are using fine-tuned LLMs for specific applications. In certain cases, the answer is yes, but not as the core piece of the application. We use AI Agents in a sophisticated prompt engineering technique called “RAG”- Retrieval Augmented Generation. In our RAG process, a fine-tuned model is used to help generate the appropriate data structures to be used to craft the prompt (more on this below).
As builders in the AI space, we thought it would be helpful to break down our considerations for fine-tuning as core to the application vs using sophisticated prompt engineering like RAG. This is a substantial decision as Fine-tuned models can increase costs by 10x per call! More on this below.
What is Fine-Tuning
Fine-tuning is a process in machine learning where a pre-trained model (e.g. LLM) is further trained on a smaller domain-specific dataset. This process allows the LLM to adapt its previously learned knowledge to a new task, making it more specialized and often improving performance on the new task. It's analogous to taking a generalist and giving them additional training in a specific field, enhancing their expertise in that area.
What is Prompt Engineering
Prompt engineering is a technique used with LLMs where users craft specific prompts or input sequences to guide the model towards producing a desired output. Instead of retraining a model, users iteratively refine their questions or instructions to get more accurate or contextually relevant answers. Think of it as the art of asking ChatGPT a question in just the right way to elicit the best possible response.
The Considerations of Fine-Tuning
Fine-tuning models is definitely useful in certain use cases, but we find solely using a fine-tuned model is not the right path for most applications. Here's why:
Capability: Fine-tuning is a labor-intensive process that requires significant technical know-how in order to do it well. Unfortunately, there are still not many AI engineers specialized in this, so the existing talent pool is quite expensive.
Uncertain Performance Uplift: It's still unclear if fine-tuning LLMs yields better results than advanced models like GPT-4 or even GPT-3.5. One of the problems facing Generative AI is there is very little testing and even fewer benchmarks to understand how your fine-tuned model is performing relative to others.
Compute Cost: Training a fine-tuned model is relatively inexpensive computationally, but running one can be cost-prohibitive for many. Querying a fine-tuned GPT model costs ~10x per call than querying a base GPT model.
Time-Intensiveness: Preparing, training, and especially testing a fine-tuned model is very time-consuming (and remember this is very expensive because AI engineers are rare).
Data Dependency: An immense amount of data (with many zeros!) is needed to feed the hunger of these models. In many use cases, you don't even have enough data.
Potential Loss of Reasoning: As you finetune your model on specific domain knowledge it could lose general reasoning capabilities.
Rigidity: Fine-tuned models aren't perpetually adaptive. New data inputs mean going down the laborious and expensive path of retraining the model.
Heavy Infrastructure: Companies can consider creating and finetuning their own on-prem LLMs, but in order to run a model even close to as good as GPT, the company must have many expensive and hard-to-get GPUs.
Below are some situations where it makes sense to use fine-tuning:
Performing a new skill or task that’s hard to articulate in a prompt (THIS IS THE MOST IMPORTANT)
Setting the style, tone, format, or other qualitative aspects
Improving reliability in producing a desired output
Correcting failures to follow complex prompts
Handling many edge cases in specific ways
The Power of Intelligent Prompt Engineering
At Yeager, we built our GenWorlds framework so that AI agents can use sophisticated data structures to create the best possible prompts. AI agents ingest a given dataset and run it through a fine-tuned model for processing into knowledge graphs, Qdrant vector stores, and mind maps, (if appropriate). Next, other AI agents autonomously pull from the right data structure (depending on the situation) to craft the best possible prompt. This technique is known as RAG.
See diagram below:
A fine-tuned model is just a tool to help create better data structures that an Agent would use in order to build a better prompt. This system would only query the fine-tuned model when it ingests data, not for every action. This is a massive cost savings, as laid out below.
Real Life Use Case — Learning & Development
We are working with a corporate training company in a highly complex and heavily regulated industry. The project is twofold:
Create and administer an AI teaching assistant covering an entire 8-month course where 1 section alone is based on an 800-page textbook. Noting the training of this material must be compliant with strict regulation
Interact, track, and personalize learning for each student.
Focusing on student interaction, it must be noted that this is not another chat with my PDF plugin. The process works like this:
User asks question on concept > framework injects the Agent’s prompts with information from [vector store/knowledge graph/mind map/fine-tuned model] > Agent creates an intelligent prompt to LLM > LLM provides a coherent, relevant, and reliable output
In the above process, intelligent prompt engineering provides massive cost savings vs. fine-tuning, and it is much easier to test. To quantify this, we ran the following quick and dirty analysis if we were to apply this system to a large US university:
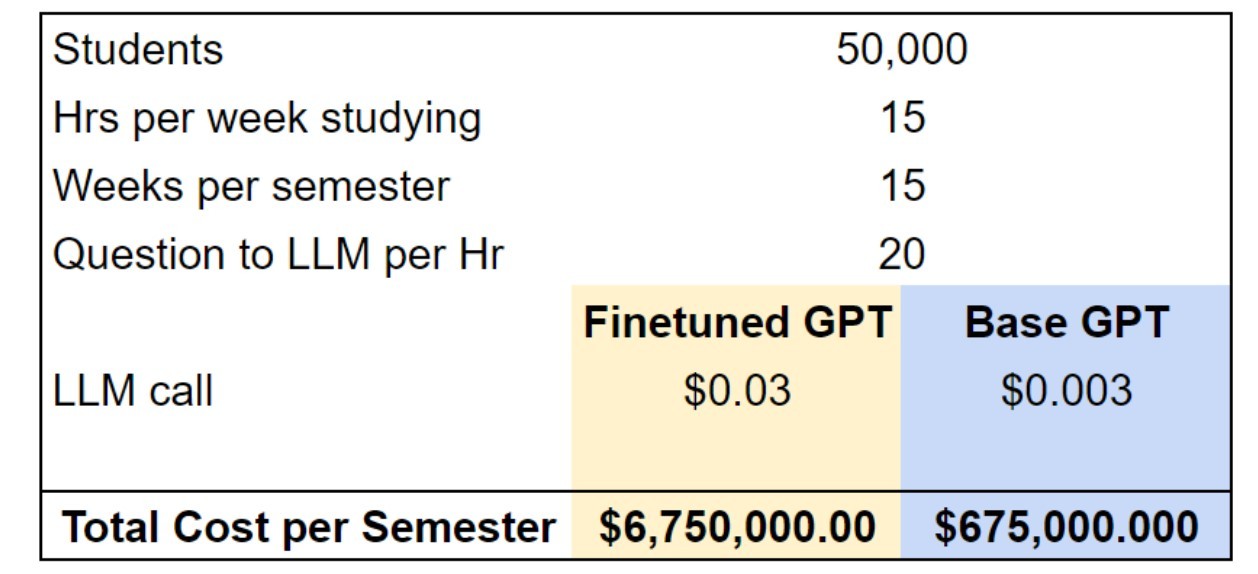
By using our system, a university would save ~$6M per semester or $12M per year. Also, RAG is far cheaper, quicker, and easier to test than fine-tuning by itself, and early indication is that it’s more effective.
Conclusion
The debate between fine-tuning and prompt engineering brings forth a fascinating crossroad in the realm of AI application development. While fine-tuning has its merits, it’s evident from our experience at Yeager that intelligent prompt engineering, especially the RAG technique, provides an agile, cost-effective, and robust alternative. Leveraging the strength of both approaches, but only using a fine-tuned model when necessary, we aim to harness the best of both worlds. As we journey forward in the rapidly evolving AI landscape, it’s imperative to be adaptive, ensuring we employ the best methodologies to achieve the most effective results.